Что если крупнейшие языковые модели можно «похудеть» в несколько раз, сохранив их мощь — и при этом сэкономить тонны воды и мегаватты электричества? Именно этим занимается команда профессора Самина Арефа из Университета Торонто.
Проблема: ИИ пожирает ресурсы
Большие языковые модели (LLM) активно обслуживают миллионы запросов, что требует миллиардов вычислений, больших объёмов электроэнергии и воды для охлаждения дата-центров.
«Выдающиеся возможности языковых моделей достигаются ценой огромных экономических и экологических затрат, которые определяются вычислениями над миллиардами параметров», — отмечает профессор Ареф.
Что такое квантизация и зачем она нужна
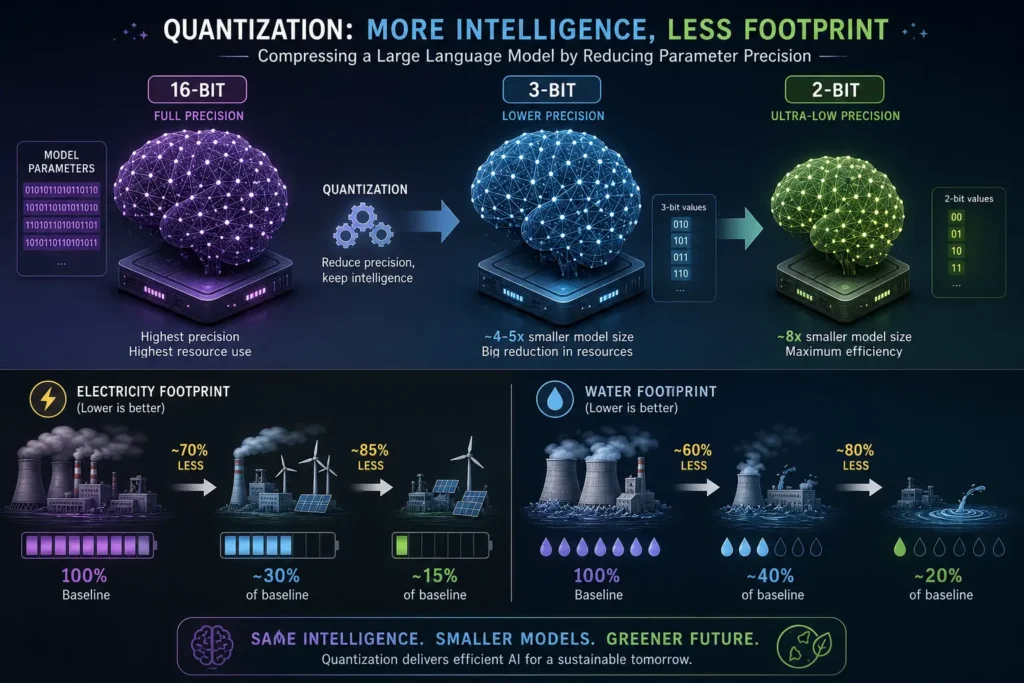
Квантизация параметров нейросети — это замена высокоточных 16-битных значений на 3- или 2-битные аналоги, что уменьшает объём модели, снижает энергопотребление и позволяет запускать её на менее мощном железе без существенной потери качества.
«Меньшие языковые модели закрывают критическую потребность в более ресурсоэффективных системах, потенциально сжатых путём квантизации параметров до значений с меньшей точностью, которые в совокупности выполняют ту же роль или роль “достаточно близкую” к оригинальной полноточной модели», — поясняет он.
Первая статья: частичное дообучение за несколько часов
Первая работа была представлена на конференции Modelling Decisions for Artificial Intelligence в Валенсии (Испания) летом 2025 года. Профессор Ареф вместе со студентом по обмену Дейу Цао из Токийского университета изучили квантизацию LLM с 7–13 миллиардами параметров.
Вместо полного переобучения, которое может занимать недели или месяцы, они предложили метод частичного дообучения (partial retraining), выполняющийся за несколько часов. Авторы уменьшили точность параметров с 16-бит до 3- и 2-бит, добавив в регуляризационный член модели штраф, приоритетизирующий наиболее влиятельные параметры. Это помогло сохранить точность моделей на высоком уровне.
Вторая статья: выравнивание распределений
На 18-й Международной конференции по агентам и искусственному интеллекту (Agents and Artificial Intelligence) в Марбелье (Испания) ранее в этом году команда, включая студентку Yixin Yin, получила премию за лучшую статью. Исследователи применили технику выравнивания распределений (distribution alignment) с измерением расстояния между статистическими распределениями при помощи срезанного расстояния Вассерштейна (sliced-Wasserstein distance).
Используя этот подход, они смогли восстановить до 20,37% точности, утерянной при агрессивной квантизации.
Выводы и перспективы
Предложенные методы показывают, что LLM можно значительно «похудеть», не жертвуя качеством ответов. Это снижает энергозатраты и объём потребляемой воды, а также открывает возможность запуска таких моделей на менее мощных устройствах.
*Yixin Yin участвовала в программе Summer Undergraduate Data Science 2025 от Data Sciences Institute (грант SUDSRY4R1P17).


